Usage recommendations
In this article:
Usage recommendations#
This section provides guidelines on using database services in K2 Cloud.
MySQL#
Service launch options#
Single DBMS instance running on a virtual machine instance in a single availability zone.
High-availability DBMS deployed in a cluster of three instances in one or three availability zones (if available in the region). The cluster can contain:
Three full-featured nodes. Data is distributed across three copies, each of which can be used independently.
Two full-featured nodes plus a cluster arbitrator. This option requires fewer resources and is, therefore, more cost-effective. Only two DBMS nodes act as worker nodes, while the third node maintains the cluster quorum. The instance with a cluster arbitrator runs using minimum resources: 2 vCPU, 4 GiB RAM, and 16 GiB volume.
High-availability solution architecture#
For MySQL clustering, we use Galera. All nodes of such a cluster are active simultaneously, so you can perform any read and write operations on them. However, the application you are using must support a DBMS configuration with multiple masters. If multiple instances of an application perform non-coordinated (non-transactional) actions on a multi-master DBMS configuration, this can lead, for example, to an increase in the number of deadlocks.
If you are not sure that your application will correctly read and write to all nodes simultaneously, it is better to use the following approaches:
Work with only one DBMS cluster node at a time and store a copy of the data on the other nodes so that they can take on the load if the first node fails.
Write to only one DBMS cluster node and use the other nodes to read data only.
A good way to implement the described approaches is to use ProxySQL. This tool receives queries from an application and redirects them to DBMS nodes. At the same time, it can, in line with the specified rules, distribute operations across specific nodes, cache DBMS responses, modify queries, etc. ProxySQL automatically detects the failure of the database cluster nodes and instantly switches over to the running nodes.
For more information about ProxySQL capabilities and setup, read the official ProxySQL documentation and project wiki. To add a DBMS server to your ProxySQL as a backend, use the instruction.
Request distribution using HAProxy#
For the usability of MySQL high-availability service, we have embedded HAProxy service into it to monitor the statuses and roles of nodes and automatically distribute requests. Requests are routed either to the first cluster node or to the next available node if the first one becomes unavailable.
HAProxy service runs on each of the cluster nodes at port tcp/5000. Therefore, you can just send a request to this port on any of the nodes, and HAProxy will route it to the correct node.
To benefit as much as possible from the high-availability service, use HAProxy ports of all nodes when connecting to MySQL. The better way is to configure another balancing service on your application side. You can either use cloud load balancer or deploy your own.
Connecting to the DBMS#
After the successful launch, info on addresses and ports that DBMS listens can be found on the MySQL database page.
MySQL instances listen to the tcp/3306 port. Use this port to connect to and then work with the DBMS.
Important
The cluster allows you to maintain the database availability even when a node fails, but only if you use all cluster endpoints rather than any one of them.
The DBMS can be managed via the standard mysql console client in Linux and using graphical tools such as dbForge Studio, MySQL Workbench, phpMyAdmin, etc.
If you want to connect to the MySQL service remotely, be sure to assign an Elastic IP to the instance with the deployed service and allow connections to the tcp/3306 port in the corresponding security group.
Important
Be careful when permitting access to MySQL from the Internet. We recommend restricting access to individual IP addresses and providing strong passwords.
PostgreSQL#
Service launch options#
Single DBMS instance running on a virtual machine instance in a single availability zone.
High-availability DBMS deployed in a cluster of three or six instances in one or three availability zones (if available in the region). The cluster can contain:
Three full-featured nodes. Data is distributed across three copies, each of which can be used independently.
Two full-featured nodes plus a cluster arbitrator. This option requires fewer resources and is, therefore, more cost-effective. Only two DBMS nodes act as worker nodes, while the third node maintains the cluster quorum. The instance with a cluster arbitrator runs using minimum resources: 2 vCPU, 4 GiB RAM, and 16 GiB volume.
Six full-featured nodes. Data is distributed across six copies, each of which can be used independently.
High-availability solution architecture#
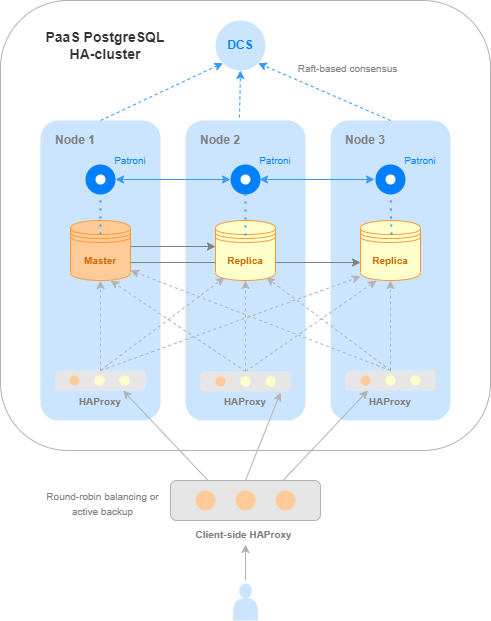
There are many ways to set up and manage replication in PostgreSQL. K2 Cloud uses Patroni to provide a high availability PostgreSQL cluster. This tool automatically monitors node status, manages replication, and switches it over if a cluster node fails.
At any time, only one cluster node can be a master, while the rest are replicas. The master node supports both read and write operations, while replicas support only read operations.
To learn the role of the specific node, send a request to Patroni RestAPI. The API is available on each node on the tcp/8008 service port. You can find the detailed instructions here.
For simplicity and ease of use of the high-availability PostgreSQL service, we built an HAProxy installation into it. HAProxy monitors node roles and automatically routes requests to the master node. HAProxy runs on all cluster nodes (except for the arbiter) on the tcp/5000 port. Thus, this port can be accessed from any node, and HAProxy will send the request to the master node.
To benefit as much as possible from the high-availability service, use HAProxy ports of all nodes when connecting to PostgreSQL. The better way is to configure another balancing service on your application side. You can either use cloud load balancer or deploy your own.
The solution architecture scheme is shown below.
Connecting to the DBMS#
After the successful launch, addresses and ports that the DBMS listens can be found on the PostgreSQL database page.
PostgreSQL instances listen to the tcp/5432 port. Patroni Rest API is available on the tcp/8008 port of these nodes. Use these ports to connect to and further work with the DBMS.
Important
The cluster allows you to maintain the database availability even when a node fails, but only if you use all cluster endpoints, not just one of them.
The DBMS can be managed via the standard psql console client in Linux or through graphical tools such as pgAdmin.
If you want to connect to the PostgreSQL service remotely, be sure to assign an Elastic IP to the instance where the service is deployed and allow connections to the tcp/5432 port in the appropriate security group.
Important
Be careful when permitting access to PostgreSQL from the Internet. We recommend restricting access to individual IP addresses and providing strong passwords.
Redis#
Service launch options#
Single DBMS instance running on a virtual machine instance in a single availability zone.
High-availability DBMS deployed in a cluster of three or six instances in one or three availability zones (if available in the region).
High-availability solution architecture#
There are two high-availability architecture options available for Redis: first, using Sentinel monitoring service and, second, featuring native clustering (in Redis terminology) starting from Redis 3.0. The first option enables high availability for small installations. The second one provides large installations with better scalability and performance.
Redis Sentinel#
K2 Cloud features three-node Sentinel configuration, with master running on one of them and replicas running on the other two (this clusterization option is not supported for a six-node cluster). Both Redis server and Redis Sentinel run on every node. In case of failures and other malfunctions, Sentinel will start automatic failover. For details about Sentinel functionality, see the official documentation.
Sentinel processes interact with each other and monitor the performance of Redis nodes. If Redis node, server or Sentinel service fail, available Sentinel processes start reselecting the master. Then, automated failover starts, the selected replica becomes the new master while the remaining replica is reconfigured to work with the new master. The applications that use Redis server are notified of the new connection address.
Note
Redis uses asynchronous replication, so such a distributed system of Redis nodes and Sentinel processes does not guarantee that confirmed transactions will be actually saved in case of failure.
High-availability Redis service#
A high-availability Redis service is deployed in a cluster consisting of three (or six) instances. Each instance has one master and one replica, and the latter interacts with a master on another node (cross-replication).
Multiple master nodes ensure high performance and linear scalability for a cluster, while having at least one replica per master ensures its high availability. For more information, read the Redis official documentation.
All master nodes share a single data space, which is divided into shards. Thus, each master contains part of the shards (sharding).
When working with a high-availability Redis service, requests are processed by masters. Any master can be accessed for read and write operations. If the requested data is in a shard on another master, then Redis itself will redirect the client to the respective instance to read them.
In the event of a failure of a master instance or the entire node on which the instance is running, automatic failover occurs to a respective replica, which takes on the master role.
Request distribution using HAProxy#
For simplicity and ease of use of the high-availability Redis service, we built an HAProxy installation into it. HAProxy monitors node statuses and roles and automatically distributes requests to only those VM instances acting as masters.
HAProxy runs on the tcp/5000 port on all cluster nodes. Thus, this port can be accessed from any node, and HAProxy will request one of the master nodes.
To benefit as much as possible from the high-availability service, use HAProxy ports of all nodes when connecting to Redis. The better way is to configure another balancing service on your application side. You can either use cloud load balancer or deploy your own.
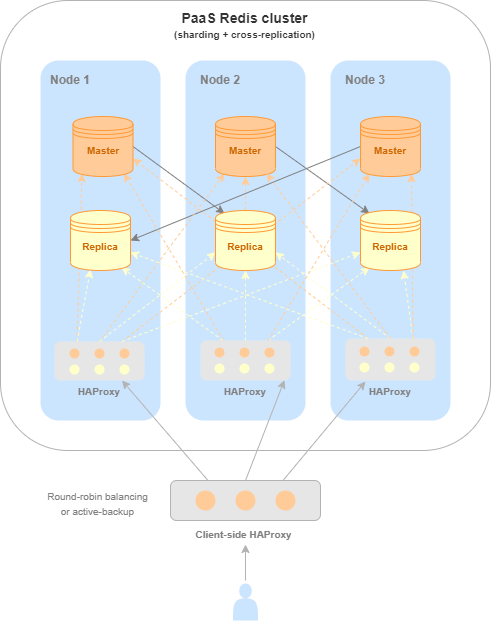
Solution architecture featuring HAProxy for a high-availability Redis service#
Connecting to the DBMS#
After the successful start, addresses and ports listened by DBMS can be found on the Redis database page. In case of a standalone service, only one endpoint is available for connection, while in case of a high-availability service, there are multiple endpoints depending on the selected architecture.
Redis master instances listen to the tcp/6379 port, while replicas listen to the tcp/6380 port. In the event of a failure of a master instance or the entire node on which the instance is running, automatic failover occurs: the replica becomes a master. Still, it continues to listen to the tcp/6380 port. Therefore, the port number alone is not enough to understand whether an instance is a master or replica if the cluster runs for a long time.
Important
The cluster allows you to maintain the database availability even when a node fails, but only if you use all cluster endpoints rather than any one of them.
Authentication in Redis#
When working in a closed environment, you don’t need to enable authentication in Redis, but you may need to password-protect your installation in an untrusted environment.
You can set the password when creating the database service. After the service has been launched with the specified password, you can access it after authentication (the AUTH command’).
The deployed Redis service can be managed via the standard redis-cli console client in Linux or through graphical tools. A good overview of graphical tools can be found in the blog.
If you want to connect to the Redis service remotely, be sure to assign an Elastic IP to the instance where the service is deployed and allow connections to the tcp/6379-6380 ports in the appropriate security group.
Important
Be careful when permitting access to Redis from the Internet. We recommend restricting access to individual IP addresses and providing strong passwords.
MongoDB#
Service launch options#
Single DBMS instance running on a virtual machine instance in a single availability zone.
High-availability DBMS deployed in a cluster of three instances in one or three availability zones (if available in the region). The cluster can contain:
Three full-featured nodes. Data is distributed across three copies, each of which can be used independently.
Two full-featured nodes plus a cluster arbitrator. This option requires fewer resources and is, therefore, more cost-effective. Only two DBMS nodes (primary and secondary) act as worker nodes, while the third node (arbiter) maintains the cluster quorum. The instance with a cluster arbitrator runs using minimum resources: 2 vCPU, 4 GiB RAM, and 16 GiB volume.
High-availability solution architecture#
A cloud-based MongoDB high-availability service is a replica set — a group of MongoDB instances maintaining the same data set through replication.
There are several roles in a replica set:
primary node for read and write operations;
secondary node for read only operations;
arbiter that neither replicates the data nor participates in user operations.
Data replication is asynchronous: the primary node performs all write operations, then the secondary node reads the description of these operations and asynchronously applies them.
If the primary node becomes unavailable, for example, crashes, the remaining cluster nodes use the quorum rule to determine which of them will take over its role. When the unavailable node is on again, it becomes the secondary one and copies the current dataset from the new primary node. Thus, the primary role can switch from one node to another throughout the cluster lifecycle.
To learn more about the replica set operation, read the official MongoDB ``documentation.
Request distribution using HAProxy#
For better experience with the high-availability MongoDB service, HAProxy is integrated into it. This component monitors the roles of nodes and redirects traffic to the current primary node of the cluster. If a role changes or the cluster’s primary node is unavailable, HAProxy automatically redirects requests to the new primary node.
HAProxy service runs on each of the cluster nodes (except for an arbitrator) at port tcp/5000. Therefore, you can send a request to any node, and HAProxy will automatically route it to the correct destination.
To benefit as much as possible from the high-availability service, we recommend using HAProxy ports on all nodes when connecting to MongoDB. You will need to configure one more load balancer on your application side. You can either use cloud-based load balancer or deploy your own one.
Connecting to the DBMS#
After the successful start, addresses and ports that the DBMS listens to appear on the MongoDB database page. MongoDB instances listen to the tcp/27017 port.
Important
The cluster allows you to maintain the database availability even when a node fails, but only if you use all cluster endpoints rather than any one of them.
MongoDB clients and drivers support a connection string, where you can specify endpoints for a replica set to detect a current primary node and switch to a new node automatically.
Generally, the connection may look like this:
mongodb://mongo1,mongo2,mongo3/?replicaSet="rsmain"
It suffices to specify several nodes for the connection and others will be detected automatically. The replicaSet in such automatically deployed clusters is always called rsmain.
The deployed MongoDB service can be managed using either the standard mongo shell console client in Linux or graphical tools, such as TablePlus or Robo 3T.
To connect to the MongoDB service remotely, follow these steps:
Open the instance page with the running MongoDB service , go to the Network and Security tab and click on the ID of the security group that you plan to use for controlling access from outside.
On the security group page, go to the Inbound rules tab.
Add an enabling rule for the tcp protocol and port
21017.Associate Elastic IP with a network interface of this instance.
Important
Be careful when permitting access to MongoDB from the Internet. We recommend restricting access to individual IP addresses and providing strong passwords.